


Audience: Machine Learning Engineer, Infrastructure Engineer, Data scientist
An important aspect of building a machine learning pipeline is the ‘workflow’. Workflow refers to the phases of a machine learning model defined and executed by the developer. A typical workflow involves phases like data collection, data cleaning, pre-processing, model building, and making predictions.
A workflow’s dependencies on data and infrastructure complicate its maintenance and reproducibility. These dependencies may not allow the user to focus on the business logic thereby reducing the performance of the model.
Flyte is your one-stop solution to resolve these data and infrastructure dependencies, focus on the business logic, and improve the efficiency of your machine learning model.
What is Flyte?
Flyte is a distributed workflow automation platform that is
Open source
Kubernetes-built
Container-native
You can build complex, mission-critical data and machine learning pipelines at scale. You can also accelerate models to production by building highly concurrent, scalable, and maintainable pipelines that scale to millions of executions and containers.
Flyte bridges the gap between creating machine learning models and setting them in production. You can execute the model and Flyte will seamlessly orchestrate it in the production environment.
Note: A ‘workflow’ in Flyte’s context is different from a machine learning workflow.
Building blocks of Flyte
- The building block of Flyte is a ‘task’. Think of it as a function with the @task decorator. It is an independent unit/s of execution that encapsulates your code. Tasks are versioned and shareable.
@task
def some_function(arguments) -> return_type:
function-body
return value
A single workflow in Flyte can be associated with multiple tasks. Below is an example of two tasks that generate a dataframe and compute descriptive statistics respectively.

- Tasks in Flyte are combined to execute them in a specific order using a workflow. A ‘workflow’ is a directed acyclic graph (DAG) of units of work encapsulated by nodes that describes the order of execution of tasks. It is specified using the @workflow decorator.
@workflow
def my_workflow(arguments) -> return_type:
function-body (Specify the order of tasks)
return value
Below is an example of a workflow that specifies the order of execution of the above-mentioned tasks. More about it here.

A ‘node’ represents a unit of work within a workflow. Generally, a node encapsulates an instance of a task and can coordinate task inputs and outputs. It behaves as a wrapper for tasks and workflows and can be visualised on the user interface.
‘Launchplans’ invoke workflow executions. You can bind a partial or complete list of inputs to be passed as arguments to create an ‘execution’ (workflow execution). Flyte automatically creates a default launch plan (with no inputs) when a workflow is serialised and registered.
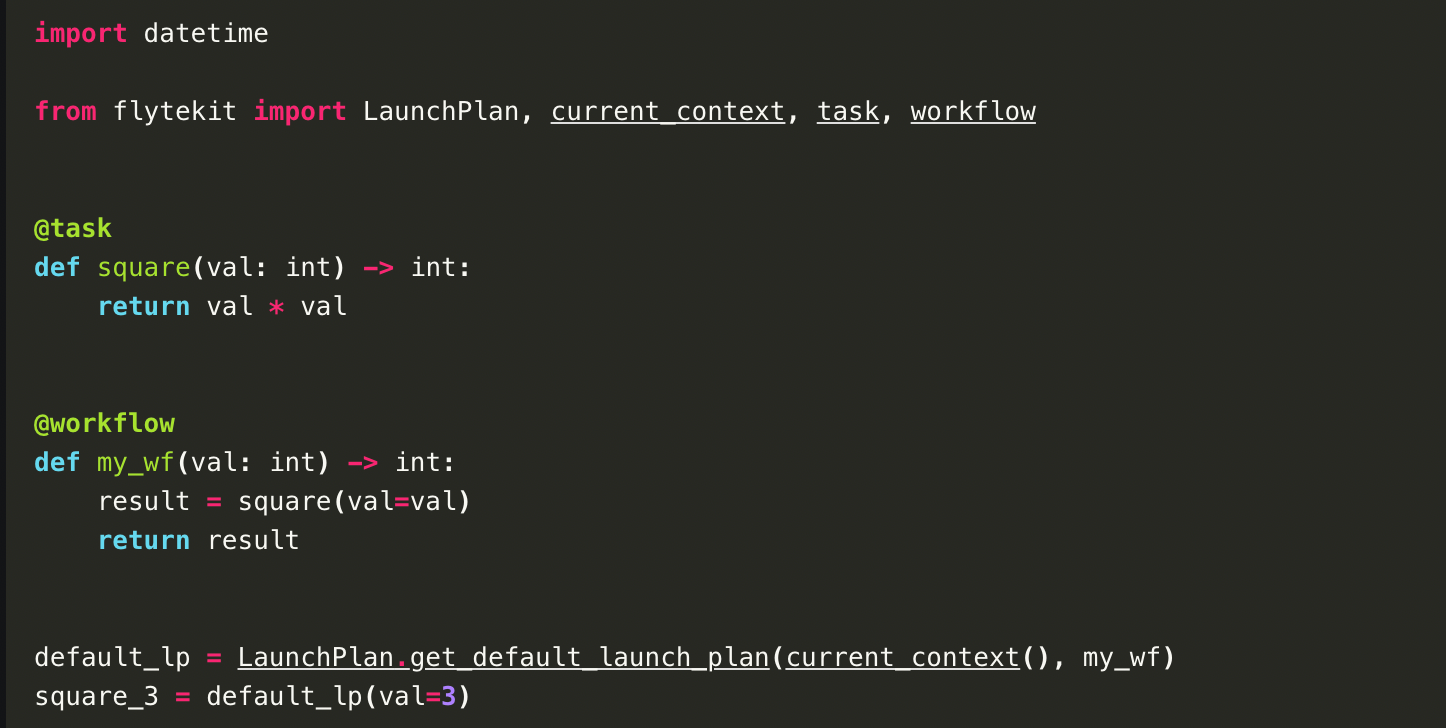
Instead of using a default launch plan, you can create one too! This way, you can supply the parameters to a launch plan instead of using the default one.

- An ‘execution’ is an instance of a workflow, node, or task.
Tip: You can involve tasks and workflows as regular Python methods, import them, and use them in other Python modules.
Other features of Flyte
Versioned
Versioned code, containerized with all the dependencies.
Versioned entities, with an option to roll back to a specific version.
Multi-tenant, scalable service to allow users to work in their own isolated repository without affecting other parts of the platform.
Cached output for every job trigger, allowing reuse (instead of re-compute), thereby saving execution time and resources.
Metadata capture (logs) for every workflow to backtrack to the source of errors.
Type system
Support for multiple data types such as Blobs, Directories, Schema, and more.
Strongly typed and parameterized tasks.
Typesafe pipeline construction, that is, every task has an interface characterized by an input and output. This means illegal pipeline construction fails during declaration, rather than at runtime.
Customization
Out-of-the-box support to run Spark jobs on K8s, Hive queries, and more.
Customizable user classes to suit specific requirements.
Integrations (SQL, Pandera, Modin) to extend Flyte, if you are ready to take a deep dive!
Miscellaneous
Ability to iterate through models.
User-friendly SDKs to run the workflows.
Ability to generate dynamic graphs to take decisions during run-time (such as tuning hyperparameters during execution, programmatically stopping the training in case of surging errors, modifying logic of code dynamically, and building AutoML pipelines).
Coming up…
My next post will be a ‘Hello World’ example using Flyte’s tasks and workflow. Stay tuned.